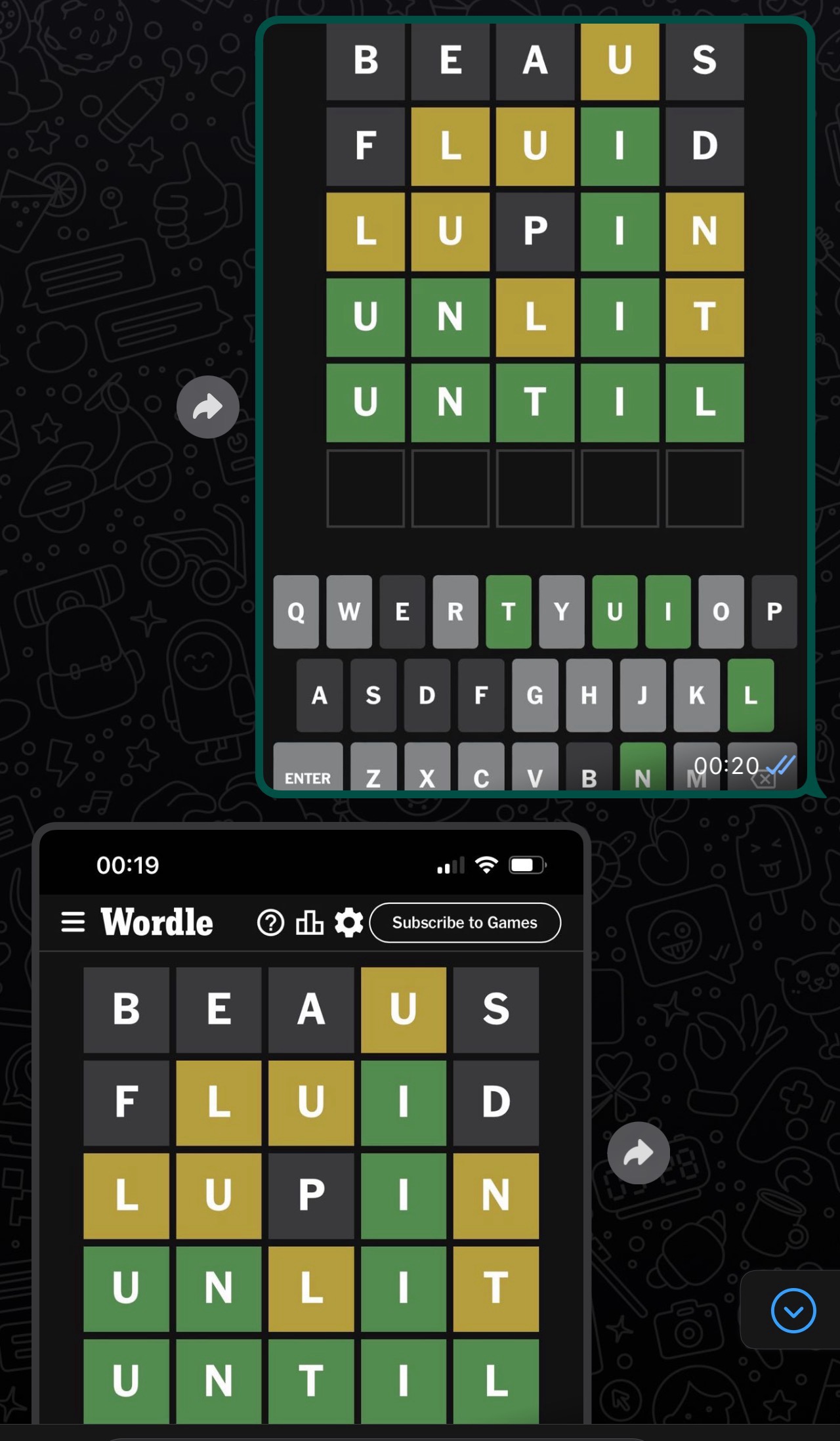
You might be surprised. It’s not uncommon for certain friend/colleague groups to settle on a good first word between their group. Which @graham later clarified that’s what they did here,
The first guess for most people is just to eliminate vowels. And the result can heavily influence that second guess.
On a level of pure randomness, the odds might look astronomical. But Wordle by its very nature eliminates that randomness.
To put it into perspective without getting into the maths, this exact scenario has happened within my friend group quite often, sometimes across more than 3 people.
My brother in law [in USA] and I share the same start word. I don’t think we’ve ever matched each other all the way through the game. I get a huge number if 4’s. R-
My PhD was Applied Maths, not statistics (which I dropped after the first year of my undergraduate degree) so I’m not really qualified to say, but I think calculating such a probability is going to be difficult. It depends how you approach the puzzle and what your thought processes are.
The word ‘lupin’ is interesting and I expect that there are many younger people (or older non-gardeners) who may not even have heard it before.
I think there are too many dependencies to calculate a reasonable probability, so I’d personally just be happy with “great minds think alike”. Or “fools seldom differ”
You’d need to know the number of five letter words with a U in them to determine the probability that you’d both pick the same word at random.
Unfortunately it wouldn’t have been picked truly randomly because neither of you knows all of the five letter words with a U in them, and so neither of you would have picked a word you didn’t know.
So we are left with the set of five letter words containing a U which both of you know. That will give you the probability of both choosing the same one. Even then, you aren’t choosing at random because you’d both likely be biased towards a word that’s in reasonably common usage.
In short - it’s very difficult with lots of very hard sums to do. And probably a bit more likely than you’d expect.
Wordle has become a bit of a research study in mathematics and data science academia, because it is quite fascinating.
I don’t think anyone has specifically tried to tackle this problem (yet), but we do now know that the human approach to the Wordle problem (eliminating as many vowels as you can first with words like audio and adieu) is flawed, and that machine learning algorithms are much better than we are.
According to information theory, soare is the best word to start, and is probably the one humans should play. But we also know from extensive machine learning testing that crane is the objective best starting word. But humans shouldn’t play it, because the word you play after is very dependant on the result of the first word, and humans aren’t going to be able to identify the best second word as well as a trained computer can.
I’m not going to test it, but my hypothesis for this scenario would be that successive same word guess between two friends who play the same starting word have an increasingly higher probability of being an identical guess.
That first guess eliminates a lot of randomness. Two friends are likely to have a pretty similar vocabulary range. They’re both probably going to use a word with U in the second guess but not in the fourth slot, along with an I or an O. There’s going to be a much smaller word pool to choose from once you factor these things into that second guess. Assuming they both have the same strategy to solving the Wordle (which is the case here) we repeat for the third and fourth too.
You always choose the same first word, so that one was guaranteed.
According to this, there were only 129 options for your second word.
129 words
chuck
chump
chunk
churn
cluck
clump
clung
couch
cough
could
count
court
crump
cumin
curio
curly
curry
curvy
dough
druid
drunk
duchy
dully
dummy
dumpy
dutch
fluff
fluid
flung
flunk
found
fruit
fully
fungi
funky
funny
furor
furry
fuzzy
gourd
gruff
grunt
guild
guilt
gulch
gully
gummy
guppy
hound
humid
humor
humph
hunch
hunky
hurry
hutch
juicy
jumpy
junto
juror
lucid
lucky
lumpy
lunch
lurch
lurid
moult
mound
mount
mourn
mouth
mucky
muddy
mulch
mummy
munch
murky
nutty
ought
outdo
outgo
pluck
plump
plunk
pouch
pound
pouty
pudgy
puffy
pulpy
punch
pupil
puppy
putty
quick
quill
quilt
quirk
quoth
rough
round
ruddy
rumor
thump
touch
tough
truck
truly
trump
trunk
truth
tulip
tumor
tunic
tutor
undid
unfit
unify
union
unity
unlit
until
unzip
Then there were only 4 words.
4 words
pupil
tulip
unlit
until
Then you were down to 2.
2 words
unlit
until
Then there was only one option left.
So that’s a 1 in (1 x 129 x 4 x 2 x 1), or 1 in 1,000.
There are some assumptions in that, like you choose from all words equally, which I’m sure isn’t true. And that 1,000 chance might be wildly different with different starting words and different answers - it won’t be 1,000 every day.